
O Elo Perdido entre o Carbono e o Silício
A princípio, a linguagem é a maior conquista da evolução humana. Inegavelmente, é através dela que estruturamos o pensamento e transmitimos cultura. Contudo, para uma máquina, a fala humana é um conjunto de ruídos desestruturados e dados não-lineares. Dessa forma, o Processamento de Linguagem Natural (NLP) surge como a ponte que traduz a semântica biológica para a lógica algorítmica.
Atualmente, em 2026, não estamos mais falando apenas de “comandos de voz” simples. Estamos vivendo a era da compreensão contextual profunda. Consequentemente, o NLP deixou de ser um recurso extra para se tornar o sistema operacional das empresas mais valiosas do mundo. Portanto, entender essa ciência é o “upgrade” necessário para qualquer profissional que pretenda sobreviver à revolução da IA.
A Evolução: Da Regra Rígida à Intuição Estatística
Antigamente, nas décadas de 50 e 60, o NLP era baseado em regras gramaticais rígidas. Se uma frase não seguisse a estrutura “Sujeito + Verbo + Predicado” pré-definida, a máquina falhava. Nesse sentido, o sistema era como um tradutor de bolso limitado.
Posteriormente, nos anos 90, vivemos a revolução estatística. Dessa maneira, em vez de ensinar regras às máquinas, começamos a alimentá-las com grandes volumes de texto para que elas calculassem a probabilidade de uma palavra seguir a outra. Todavia, o verdadeiro salto quântico ocorreu com a chegada do Deep Learning. Hoje em dia, as máquinas não “calculam” apenas palavras; elas capturam a essência do contexto.
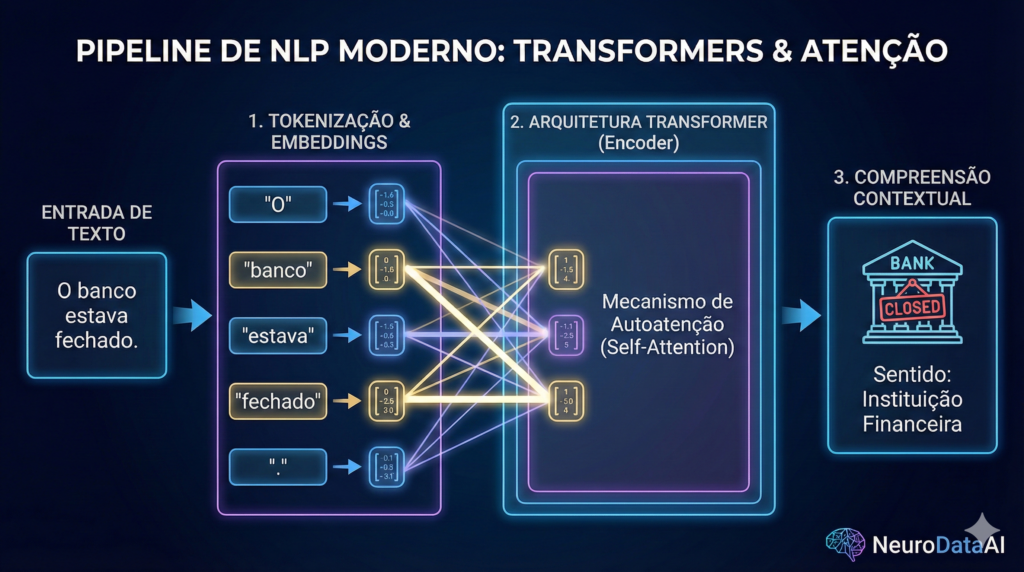
O Pipeline do NLP: Preparando o Hardware Mental
Antes de tudo, para que um computador entenda o que você diz, os dados precisam ser “limpos”. Este processo é conhecido como pré-processamento e envolve etapas críticas:
A. Tokenização e Normalização
De fato, a máquina não lê frases; ela lê “tokens”. Dessa forma, a frase “O robô entende a fala” é quebrada em pequenas unidades. Além disso, removemos as Stop Words (palavras comuns como “o”, “a”, “de”) que não agregam valor semântico direto para o modelo estatístico inicial.
B. Stemming e Lemmatização
Nesse contexto, precisamos reduzir as palavras à sua raiz. “Falando”, “Falei” e “Falar” tornam-se apenas “Falar”. Assim sendo, simplificamos o dicionário da máquina para que ela foque no conceito, não na conjugação.
C. Vetorização (Word Embeddings)
Aqui está a mágica: transformamos palavras em números. Sob o mesmo ponto de vista, no espaço vetorial, a palavra “Rei” está matematicamente próxima de “Rainha”.
$$Rei – Homem + Mulher = Rainha$$
Certamente, essa capacidade de representar conceitos em dimensões matemáticas é o que permite à IA realizar analogias e compreender nuances que antes eram exclusivas dos seres humanos.
NLP e a Neurociência: O Upgrade Biológico
Frequentemente, na NeuroDataAI, comparamos o processamento de linguagem das máquinas com o Área de Broca e a Área de Wernicke no cérebro humano. Nesse sentido, enquanto o cérebro usa impulsos elétricos entre neurônios, o NLP usa funções de ativação em redes neurais artificiais.
Por outro lado, o desafio das máquinas ainda é a pragmática — a capacidade de entender a intenção por trás das palavras. Todavia, com o avanço das arquiteturas , essa lacuna está diminuindo a cada milissegundo.
O Fim da Era Sequencial: O Gargalo das RNNs
A princípio, as primeiras redes neurais voltadas para linguagem, como as RNNs (Redes Neurais Recorrentes) e LSTMs, processavam a informação palavra por palavra. Todavia, esse método apresentava um problema crítico: a perda de memória a longo prazo. Dessa forma, quando a máquina chegava ao final de um parágrafo, ela já havia “esquecido” o sujeito da primeira frase.
Consequentemente, os modelos eram incapazes de entender textos complexos ou referências distantes. Nesse sentido, era necessário um “upgrade” arquitetural que permitisse ao sistema olhar para todo o texto simultaneamente. Inegavelmente, esse salto ocorreu em 2017 com o histórico artigo “Attention is All You Need”, que introduziu a arquitetura Transformer.
O Mecanismo de Atenção: Onde a Mágica Acontece
Sob o mesmo ponto de vista da neurociência, o cérebro humano não presta atenção em todas as palavras com a mesma intensidade. Por exemplo, na frase “O banco estava fechado porque o gerente perdeu a chave”, seu cérebro foca em “banco” e “gerente” para entender que se trata de uma instituição financeira, e não de um assento de praça.
Da mesma maneira, o mecanismo de Self-Attention (Autoatenção) permite que a máquina atribua “pesos” diferentes para cada palavra em relação às outras. Portanto, a IA cria uma teia de conexões matemáticas onde cada termo “sabe” qual é a sua importância no contexto global.
A Matemática da Atenção
Para os entusiastas da voltagem técnica, a função de atenção é calculada através de três matrizes principais: Queries (Q), Keys (K) e Values (V). A equação simplificada em LaTeX é:
$$Attention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Dessa forma, a máquina calcula a similaridade entre o que ela procura (Query) e o que está disponível (Key), aplicando esse resultado aos valores semânticos (Value). Assim sendo, o NLP moderno deixou de ser uma tradução de dicionário para se tornar uma análise de relevância estatística em tempo real.
A Ascensão dos LLMs (Large Language Models)
Além disso, a arquitetura Transformer permitiu o treinamento em escala massiva. Nesse contexto, surgiram os LLMs, como as séries GPT, Claude e Llama. Inegavelmente, em 2026, esses modelos atingiram um patamar onde a distinção entre a resposta de uma máquina e de um humano é praticamente imperceptível em testes de Turing avançados.
Entretanto, o segredo não está apenas no código, mas no volume de parâmetros. Em outras palavras, quanto mais conexões neurais artificiais o modelo possui, maior é a sua capacidade de capturar nuances, sarcasmo e dialetos técnicos. Contudo, isso exige uma infraestrutura de hardware de altíssima performance.
O Contexto é Rei: Do Estático ao Dinâmico
Frequentemente, no NLP antigo, a palavra “manga” teria sempre o mesmo valor numérico. Por outro lado, com os modelos modernos de Embeddings dinâmicos, a IA consegue distinguir se você está falando da fruta ou da parte de uma camisa.
Certamente, essa capacidade de desambiguação é o que permite às máquinas compreenderem a fala humana em toda a sua complexidade. Assim sendo, o NLP atual não apenas “lê” símbolos; ele simula uma compreensão semântica que antes julgávamos ser uma exclusividade biológica.
Neurociência vs. IA: Atenção Sintética
Sobretudo, a arquitetura de atenção nas máquinas é inspirada na nossa própria capacidade de foco executivo. Nesse sentido, enquanto o nosso cérebro filtra ruídos para focar em uma conversa em um restaurante barulhento, o Transformer filtra bilhões de dados para encontrar o sentido em uma consulta de busca.
Todavia, há uma diferença fundamental: as máquinas não possuem (ainda) a consciência do significado. Dessa maneira, elas são exímias manipuladoras de símbolos, mas a “centelha” da compreensão real continua sendo o grande debate da fronteira tecnológica de 2026.
Concluímos agora o nosso guia de alta voltagem sobre a tecnologia que está redefinindo as fronteiras entre a biologia e o código. Se nas partes anteriores desconstruímos o hardware matemático e os algoritmos de atenção, agora vamos focar na execução.
Em 2026, o Processamento de Linguagem Natural (NLP) não é apenas uma curiosidade técnica; é o motor econômico da nova era da informação.
Do Código ao Lucro: Aplicações de NLP em 2026
A princípio, a maior mudança que vimos nos últimos anos foi a transição do NLP “passivo” (que apenas classifica textos) para o NLP “generativo” e “estratégico”. Inegavelmente, as empresas que ignoram o poder da fala automatizada estão operando com um hardware obsoleto.
A. Análise de Sentimento em Larga Escala
Atualmente, marcas globais utilizam o Processamento de Linguagem Natural para monitorar bilhões de conversas em tempo real. Dessa forma, não se trata apenas de saber se o cliente está “feliz” ou “triste”, mas de identificar nuances de sarcasmo, urgência e intenção de compra. Consequentemente, o marketing tornou-se uma ciência preditiva, onde a máquina antecipa crises antes mesmo que elas se tornem virais.
B. Hiper-Personalização e Atendimento
Além disso, os chatbots de 2026 evoluíram para “Agentes Cognitivos”. Nesse sentido, graças aos avanços em LLMs, esses sistemas possuem memória de longo prazo e capacidade de resolver problemas complexos sem intervenção humana. Portanto, o ROI de projetos de IA que utilizam NLP disparou, reduzindo custos operacionais em até 70% em setores de suporte técnico.
A Fronteira da Voz: STT + NLP + TTS
Sob o mesmo ponto de vista, a compreensão da “fala” vai além do texto escrito. O ecossistema completo envolve três pilares:
- Speech-to-Text (STT): Transcrição fonética para dados.
- NLP: A compreensão semântica (o cérebro da operação).
- Text-to-Speech (TTS): A síntese de voz com entonação emocional.
De fato, em 2026, a latência desses sistemas caiu para menos de 200ms, permitindo diálogos fluidos que são indistinguíveis de uma conversa humana. Assim sendo, interfaces de voz estão substituindo telas em dispositivos de IoT e veículos autônomos.
Os Desafios Éticos e a “Caixa Preta”
Todavia, nem tudo são bits perfeitos. O Processamento de Linguagem Natural enfrenta desafios críticos de ética e governança. Nesse contexto, destacamos três problemas principais:
- Vieses Algorítmicos: Como as máquinas aprendem com dados humanos, elas frequentemente replicam preconceitos históricos.
- Alucinações: A tendência de modelos generativos criarem fatos fictícios com extrema confiança.
- Privacidade de Dados: O dilema de treinar modelos em conversas privadas sem violar a soberania do usuário.
Certamente, o upgrade ético é tão importante quanto o upgrade técnico. Dessa maneira, a transparência algorítmica tornou-se o novo padrão ouro para empresas de tecnologia de alta performance.
O Futuro: Multimodalidade e Cognição Simbólica
Frequentemente, perguntam-nos na NeuroDataAI: “Qual o próximo passo?”. A resposta reside na Multimodalidade. Em outras palavras, o NLP deixará de ser uma disciplina isolada para se fundir com a Visão Computacional.
Assim, as máquinas não apenas lerão o que você escreve, mas observarão sua expressão facial e o tom de sua voz para interpretar o significado real. Dessa forma, entraremos na era da “Empatia Sintética”, onde o hardware será capaz de oferecer suporte emocional baseado em dados biométricos e linguísticos.
Tabela Comparativa: NLP Clássico vs. NLP Moderno (2026)
| Característica | NLP Clássico (Regras/Estatística) | NLP Moderno (Transformers/LLMs) |
| Compreensão | Baseada em palavras-chave e sintaxe rígida. | Baseada em contexto global e semântica. |
| Memória | Curto alcance (esquece o início da frase). | Longo alcance (mantém contexto de livros inteiros). |
| Flexibilidade | Precisa de regras para cada língua. | Multilíngue por natureza (Zero-shot learning). |
| Custo de Hardware | Baixo (roda em CPUs simples). | Altíssimo (exige clusters de GPUs/TPUs). |
Link interno: Veja nosso artigo ROI de Projetos de IA: O Segredo para Não Queimar Dinheiro em 2026
Conclusão: O Upgrade Linguístico é Agora
Em suma, o Processamento de Linguagem Natural é a ciência que finalmente deu voz às máquinas e ouvidos ao silício. Inegavelmente, estamos vivendo a maior revolução na comunicação desde a invenção da prensa de Gutenberg. Portanto, dominar ou implementar essas ferramentas não é mais uma opção, mas o requisito básico para quem deseja liderar em 2026.
Lembre-se: A tecnologia entende a fala, mas a estratégia ainda depende da sua mente. Faça o upgrade agora e transforme o ruído de dados em uma sinfonia de resultados.