Overfitting e underfitting em Machine Learning são dois problemas fundamentais que surgem durante o treinamento de modelos preditivos. Desde o início, compreender esses conceitos ajuda a evitar erros comuns e melhora bastante a qualidade dos projetos de ciência de dados.
De maneira geral, esses problemas indicam quando um modelo aprende demais ou aprende de menos com os dados disponíveis. Como consequência, o desempenho pode parecer bom em alguns cenários, porém falhar quando aplicado a dados reais.
Ao longo deste artigo, você vai entender o que é overfitting e underfitting em Machine Learning, além de ver exemplos simples e aprender como identificar e evitar cada situação na prática.
O que é underfitting em Machine Learning
Antes de tudo, o underfitting em Machine Learning ocorre quando o modelo é simples demais para capturar os padrões presentes nos dados. Em outras palavras, o algoritmo não consegue aprender nem mesmo as relações mais básicas.
Nesse cenário, o modelo apresenta erro elevado tanto no conjunto de treino quanto no de teste. Portanto, isso indica claramente que o aprendizado foi insuficiente.
Exemplo simples de underfitting
Por exemplo, imagine que você queira prever o preço de casas utilizando apenas o tamanho do imóvel. Entretanto, se o preço também depende de localização, idade e padrão da construção, um modelo muito simples irá ignorar essas variáveis.
Como resultado:
- O erro permanece alto
- As previsões ficam imprecisas
- O desempenho não melhora, mesmo com mais dados
Assim, esse é um caso clássico de underfitting em Machine Learning.
Principais causas de underfitting
- Modelo excessivamente simples
- Poucas variáveis relevantes
- Tempo de treinamento insuficiente
- Dados mal preparados
O que é overfitting em Machine Learning
Por outro lado, o overfitting em Machine Learning acontece quando o modelo aprende demais os dados de treino. Nesse caso, ele acaba memorizando padrões específicos, inclusive ruídos, e perde a capacidade de generalizar.
Como consequência, o desempenho no treino costuma ser excelente. No entanto, ao avaliar dados novos, o erro aumenta de forma significativa.
Exemplo simples de overfitting
Imagine, por exemplo, um modelo que classifica clientes como “compradores” ou “não compradores”. Se o modelo for muito complexo, ele pode aprender exceções raras presentes apenas no conjunto de treino.
Dessa forma:
- Acurácia no treino fica muito alta
- Acurácia no teste cai consideravelmente
- O modelo falha em situações reais
Portanto, esse comportamento caracteriza claramente o overfitting em Machine Learning.
Principais causas de overfitting
- Modelos excessivamente complexos
- Grande número de parâmetros
- Poucos dados de treinamento
- Ausência de regularização
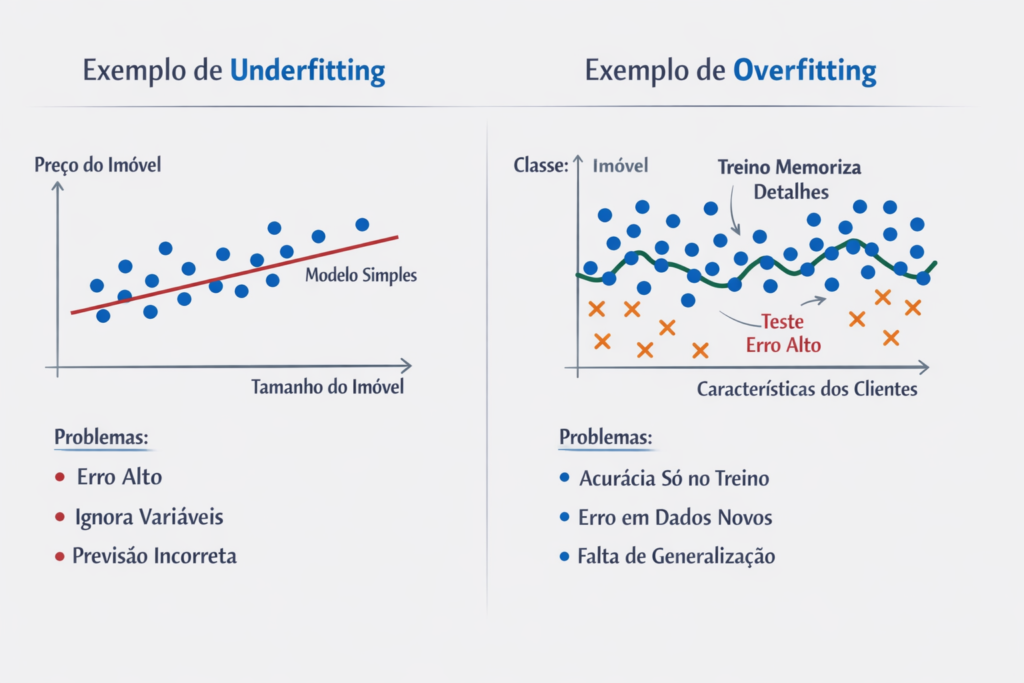
Diferença entre overfitting e underfitting
Para deixar a distinção clara, vale resumir:
- Underfitting: o modelo aprende pouco e erra sempre
- Overfitting: o modelo aprende demais e erra fora do treino
Em termos técnicos, essa diferença está diretamente relacionada ao equilíbrio entre viés (bias) e variância (variance). Ou seja, modelos muito simples tendem a alto viés, enquanto modelos muito complexos apresentam alta variância.
Como identificar overfitting e underfitting na prática
Na prática, identificar esses problemas exige comparação entre desempenho em treino e teste. Por isso, separar corretamente os dados é essencial.
Sinais de underfitting
- Baixa performance no treino
- Baixa performance no teste
- Curvas de aprendizado quase planas
Sinais de overfitting
- Performance muito alta no treino
- Performance baixa na validação
- Grande diferença entre treino e teste
Assim, avaliar métricas em dados não vistos é uma etapa obrigatória.
Como evitar underfitting
Para reduzir o underfitting em Machine Learning, algumas estratégias ajudam bastante. Primeiramente, você pode aumentar a complexidade do modelo. Além disso, incluir variáveis relevantes costuma trazer bons resultados.
Outras ações importantes incluem:
- Treinar o modelo por mais épocas
- Melhorar a engenharia de features
- Ajustar corretamente hiperparâmetros
Em muitos casos, apenas enriquecer os dados já resolve o problema.
Como evitar overfitting
Da mesma forma, evitar o overfitting em Machine Learning exige boas práticas. Entre as principais, destacam-se:
- Aumentar o volume de dados
- Aplicar regularização (L1 ou L2)
- Utilizar validação cruzada
- Reduzir a complexidade do modelo
- Usar dropout em redes neurais
Além disso, monitorar constantemente as métricas de validação ajuda a detectar o problema cedo.

Bloco visual: resumo rápido
Para facilitar a memorização, veja um resumo direto:
- Underfitting → modelo aprende pouco
- Overfitting → modelo aprende demais
- Melhor cenário → equilíbrio entre simplicidade e complexidade
- Avaliação correta → sempre em dados não vistos
Link interno recomendado
Para complementar este conteúdo, veja também nosso artigo:
Aprendizado supervisionado e não supervisionado: o que é e qual a diferença?
Link externo recomendado
A documentação oficial do scikit-learn explica detalhadamente o trade-off entre bias e variance:
Underfitting vs. Overfitting
Conclusão
Em resumo, compreender overfitting e underfitting em Machine Learning é essencial para criar modelos confiáveis e aplicáveis no mundo real. Enquanto modelos simples demais falham em aprender, modelos complexos demais falham em generalizar.
Portanto, comece com soluções simples, avalie corretamente e ajuste a complexidade aos poucos. Dessa maneira, você reduz erros, melhora resultados e evolui com mais consistência em projetos de ciência de dados.