Por que Ciência de Dados não é só Machine Learning é uma dúvida comum entre iniciantes na área. Por isso, esclarecer essa diferença ajuda a evitar expectativas irreais e decisões técnicas equivocadas. Além disso, essa compreensão melhora a qualidade de projetos e forma profissionais mais completos.
No entanto, a popularização do Machine Learning criou a impressão de que ele define toda a área. Ou seja, muitos ignoram etapas fundamentais que vêm antes e depois dos modelos.
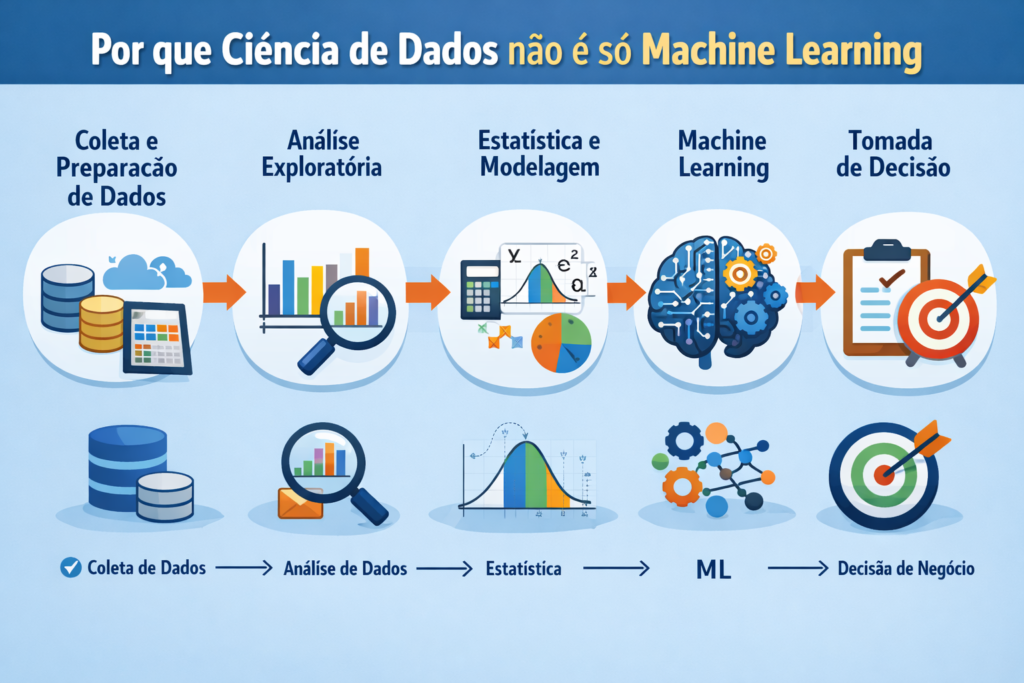
Ciência de Dados vai além de algoritmos
A Ciência de Dados é um processo completo de geração de valor a partir de dados. Dessa forma, ela envolve coleta, preparação, análise, interpretação e comunicação de resultados.
Machine Learning é apenas uma das ferramentas disponíveis. Além disso, muitos projetos de dados bem-sucedidos sequer utilizam modelos preditivos avançados. Em vários casos, análises estatísticas e exploratórias resolvem o problema.
Portanto, reduzir Ciência de Dados a Machine Learning limita o potencial da área e aumenta a taxa de falha em projetos reais.
O papel da análise exploratória de dados
Antes de qualquer modelo, dados precisam ser compreendidos. Por isso, a análise exploratória é uma das etapas mais importantes da Ciência de Dados.
Nessa fase, o profissional investiga padrões, distribuições e inconsistências. Além disso, identifica problemas de qualidade, como dados faltantes ou enviesados. Sem esse passo, modelos aprendem padrões incorretos.
Machine Learning depende diretamente dessa etapa. Ou seja, sem análise exploratória, algoritmos sofisticados produzem resultados frágeis.
Estatística como base da Ciência de Dados
A estatística sustenta decisões em Ciência de Dados. Dessa forma, ela permite avaliar incertezas, testar hipóteses e interpretar resultados.
Mesmo em projetos com Machine Learning, métricas estatísticas validam modelos. Além disso, conceitos como variância, correlação e inferência aparecem constantemente.
Portanto, Ciência de Dados sem estatística vira apenas experimentação sem critério. Isso reforça que a área não pode ser reduzida a algoritmos.
Engenharia e preparação de dados
Grande parte do tempo em projetos de Ciência de Dados é dedicada à preparação dos dados. Por isso, limpeza, transformação e organização são etapas centrais.
Dados raramente chegam prontos. Além disso, integrar fontes diferentes exige decisões técnicas cuidadosas. Sem esse trabalho, modelos não funcionam corretamente.
Machine Learning entra apenas depois dessa base estar sólida. Dessa forma, a Ciência de Dados começa muito antes do treinamento de modelos.
Tomada de decisão e contexto de negócio
Ciência de Dados existe para apoiar decisões. Portanto, entender o contexto do problema é essencial.
Modelos não decidem sozinhos. Além disso, resultados precisam ser interpretados à luz de objetivos estratégicos. Um modelo preciso pode ser inútil se não responder à pergunta certa.
Por isso, a comunicação dos resultados é parte da Ciência de Dados. Visualizações, relatórios e narrativas orientam ações práticas.
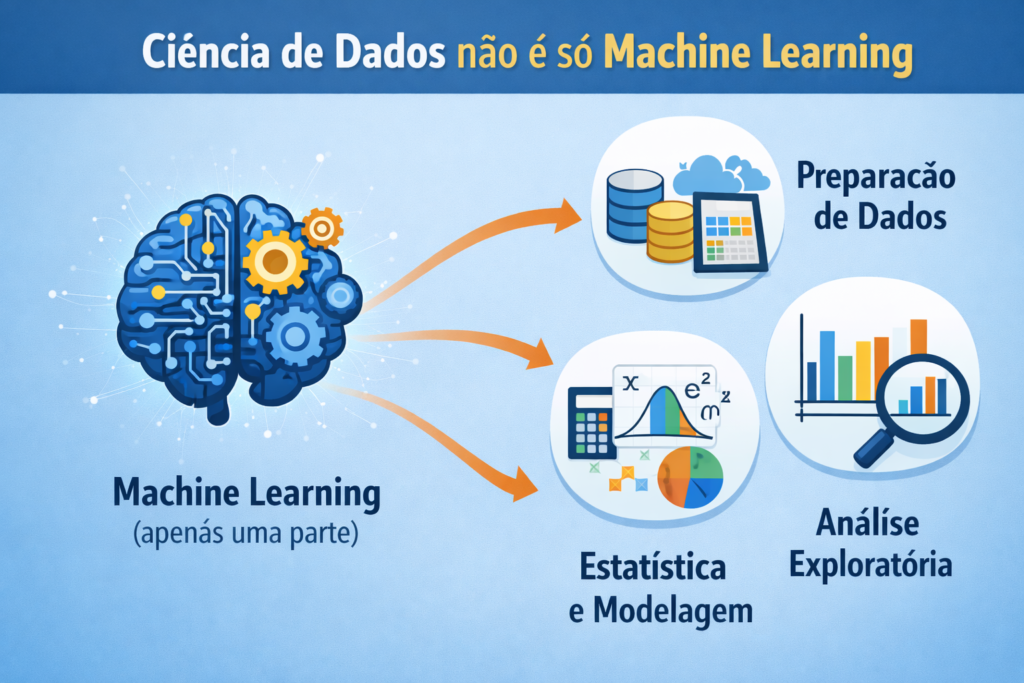
Quando Machine Learning não é necessário
Nem todo problema exige Machine Learning. Em muitos casos, regras simples ou análises descritivas resolvem a demanda.
Aplicar algoritmos complexos sem necessidade aumenta custos e riscos. Além disso, modelos difíceis de explicar podem gerar resistência organizacional.
Portanto, um bom cientista de dados sabe quando NÃO usar Machine Learning. Essa decisão demonstra maturidade técnica.
Base teórica: Processo KDD de Fayyad
A visão de Ciência de Dados como processo completo tem base no KDD (Knowledge Discovery in Databases), proposto por Usama Fayyad no contexto acadêmico em 1996.
O modelo define Ciência de Dados como uma sequência de etapas: seleção, preparação, transformação, mineração e interpretação dos dados. O foco central é a geração de conhecimento útil.
A mineração de dados, onde se encaixa o Machine Learning, é apenas uma etapa do processo. Ou seja, o KDD reforça que Ciência de Dados é muito mais ampla do que algoritmos.
Erros comuns ao reduzir Ciência de Dados a Machine Learning
Um erro frequente é começar projetos escolhendo o algoritmo. Dessa forma, o problema real fica em segundo plano.
Outro erro é ignorar qualidade de dados. No entanto, dados ruins produzem modelos ruins, independentemente da técnica usada.
Também é comum subestimar a comunicação dos resultados. Por isso, insights acabam não sendo utilizados.
Link interno: Veja o nosso artigo Machine Learning: o que é e como funciona na prática
Conclusão
Em resumo, por que Ciência de Dados não é só Machine Learning se explica porque a área envolve todo o ciclo de transformação de dados em decisões. Portanto, Machine Learning é uma ferramenta importante, mas não define a Ciência de Dados como um todo.