Aprendizado Supervisionado vs. Não Supervisionado: O Guia de Elite para Cientistas de Dados
Resumo Estratégico: A grande diferença entre os dois modelos reside na presença de rótulos (labels). No aprendizado supervisionado, treinamos a IA com respostas conhecidas; no não supervisionado, permitimos que a máquina descubra padrões ocultos por conta própria.
No ecossistema da NeuroDataAI, acreditamos que a Inteligência Artificial deve espelhar a eficiência do cérebro humano. Assim como aprendemos conceitos através de exemplos guiados ou pela simples observação do mundo, os algoritmos de Machine Learning dividem-se em duas grandes filosofias.
Escolher a abordagem correta é o que separa um modelo de alta performance de um projeto caro e ineficiente. Vamos decifrar esse mapa agora.
Comparativo Direto: Supervisionado vs. Não Supervisionado
| Característica | Aprendizado Supervisionado | Aprendizado Não Supervisionado |
| Dados de Entrada | Rotulados (Labeled Data) | Não rotulados (Unlabeled Data) |
| Objetivo Principal | Prever resultados (Output) | Descobrir padrões ocultos |
| Feedback | Direto (O modelo sabe se errou) | Nenhum (O modelo agrupa por lógica) |
| Principais Tarefas | Classificação e Regressão | Agrupamento (Clustering) |
| Exemplo Prático | Prever preço de imóveis | Segmentação de clientes |
O Paradigma do Aprendizado de Máquina em 2026
Primeiramente, é fundamental compreender que o aprendizado de máquina (Machine Learning) não é uma entidade única, mas sim um conjunto diversificado de abordagens desenhadas para extrair conhecimento a partir de dados. Nesse sentido, os conceitos de aprendizado supervisionado e não supervisionado formam os pilares fundamentais sobre os quais quase toda a inteligência artificial moderna é construída. Consequentemente, para qualquer profissional que atue na interseção entre Ciência de Dados e Neurociência, dominar essas diferenças é o primeiro passo para o sucesso técnico.
Além disso, vivemos em uma era onde o volume de dados gerados ultrapassa a nossa capacidade manual de rotulação. Portanto, entender quando aplicar a supervisão algorítmica ou permitir que a máquina descubra padrões de forma autônoma é uma decisão estratégica de alto impacto. Dessa maneira, este guia explorará detalhadamente as mecânicas, as matemáticas e as aplicações práticas de ambas as vertentes, proporcionando uma visão clara de como elas moldam o futuro da tecnologia.
O que é o Aprendizado Supervisionado: A Máquina com um Mentor
Para começarmos, o aprendizado supervisionado pode ser visualizado como um processo de ensino com o auxílio de um mentor. Nesse modelo, o algoritmo é treinado utilizando um conjunto de dados que já contém as respostas corretas, conhecidas como “rótulos” (labels). Em outras palavras, fornecemos ao computador tanto as perguntas quanto as respostas, para que ele aprenda a mapear a relação entre elas.
Por exemplo, se quisermos que uma IA identifique tumores em exames de neuroimagem, forneceremos milhares de imagens onde especialistas já marcaram o que é “saudável” e o que é “patológico”. Como resultado, o modelo ajusta seus parâmetros internos através de um processo chamado minimização da função de perda (Loss Function). Dessa forma, o objetivo final é que, ao ser apresentado a um dado inédito e sem rótulo, o algoritmo seja capaz de prever a saída correta com alta precisão.
Tipos de Problemas Supervisionados
Basicamente, o aprendizado supervisionado divide-se em duas grandes categorias:
- Classificação: Onde a saída é uma categoria discreta (ex: Gato ou Cachorro, Spam ou Não Spam). Nesse caso, algoritmos como Support Vector Machines (SVM) e Florestas Aleatórias são amplamente utilizados.
- Regressão: Onde a saída é um valor numérico contínuo (ex: prever o preço de um imóvel ou o nível de dopamina no cérebro). Portanto, modelos de Regressão Linear e Redes Neurais são as ferramentas de escolha.
O que é o Aprendizado Não Supervisionado: A Descoberta da Estrutura
Em contrapartida, o aprendizado não supervisionado opera em um cenário muito mais desafiador e, muitas vezes, mais próximo da realidade biológica humana. Nesse contexto, o algoritmo não recebe rótulos ou respostas corretas. Pelo contrário, ele é apresentado a um mar de dados brutos e tem como missão encontrar padrões, semelhanças ou estruturas ocultas por conta própria.
Isto ocorre porque, em muitos casos, não sabemos o que estamos procurando ou a rotulação manual é inviável. Dessa maneira, o aprendizado não supervisionado é a ferramenta definitiva para a exploração de dados (Data Discovery). Além disso, ele permite que a inteligência artificial identifique segmentos de mercado, comportamentos anômalos em redes neurais ou agrupamentos de genes que a mente humana poderia ignorar. Consequentemente, essa abordagem é essencial para a inovação em campos onde o conhecimento prévio é limitado.
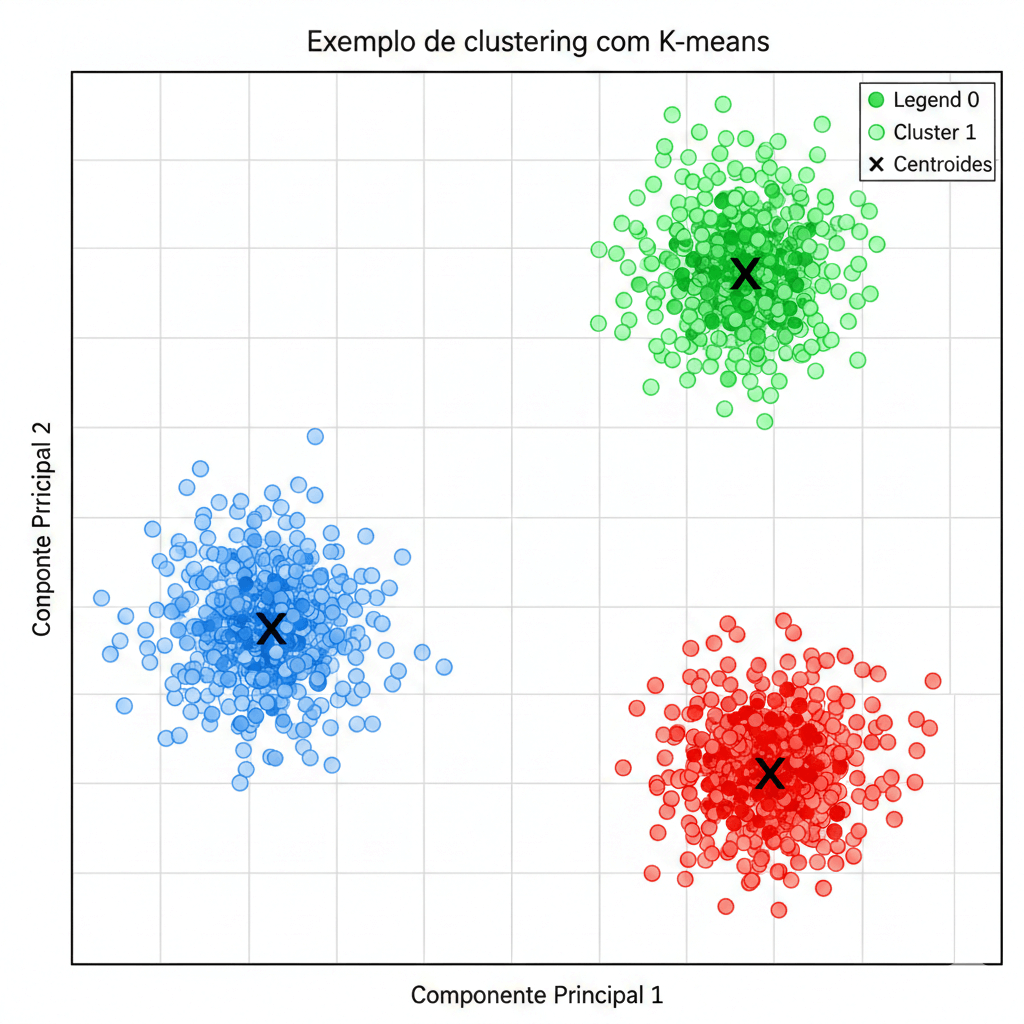
Tipos de Problemas Não Supervisionados
Dentro dessa categoria, os algoritmos costumam focar em:
- Agrupamento (Clustering): Dividir os dados em grupos baseados em similaridade (ex: K-means).
- Redução de Dimensionalidade: Simplificar dados complexos mantendo as informações essenciais (ex: PCA ou t-SNE). Nesse sentido, é vital para visualizar dados de alta dimensão, como a atividade de bilhões de neurônios.
- Associação: Descobrir regras que descrevem grandes porções de dados (ex: pessoas que compram o produto A também compram o B).

Comparação Direta: Supervisionado vs. Não Supervisionado
Para facilitar a compreensão, é útil colocar essas duas abordagens lado a lado. Enquanto o aprendizado supervisionado foca em previsão, o aprendizado não supervisionado foca em descrição. Além do mais, as métricas de sucesso diferem drasticamente entre as duas.
Tabela Comparativa de Atributos
| Atributo | Aprendizado Supervisionado | Aprendizado Não Supervisionado |
| Dados de Entrada | Dados Rotulados (Input + Output) | Dados Não Rotulados (Input apenas) |
| Objetivo Principal | Prever resultados para novos dados | Descobrir padrões e estruturas ocultas |
| Feedback | Recebe feedback imediato do erro | Não recebe feedback externo |
| Complexidade | Geralmente mais simples de avaliar | Exige interpretação subjetiva humana |
| Algoritmos Comuns | Regressão, Árvores de Decisão, SVM | K-Means, PCA, DBSCAN |
| Métricas | Acurácia, Precisão, Recall, F1-Score | Silhouette Score, Inertia, Entropia |
O Custo da Rotulação e o Problema do Viés
Um ponto crucial que devemos discutir é a dependência do aprendizado supervisionado em relação à qualidade dos rótulos. Infelizmente, rotular dados é um processo lento, caro e sujeito a erros humanos. Por exemplo, se um grupo de médicos discordar sobre a classificação de uma imagem, o modelo herdará essa incerteza. Consequentemente, o aprendizado supervisionado pode propagar preconceitos e vieses contidos nos dados históricos.
Por outro lado, o aprendizado não supervisionado é “cego” aos rótulos, o que pode parecer uma vantagem. Todavia, isso traz o risco de o algoritmo encontrar padrões que não têm significado prático ou que são meramente ruídos estatísticos. Dessa maneira, a escolha entre as duas abordagens depende não apenas dos dados disponíveis, mas também do nível de confiança que temos nas categorias pré-estabelecidas. Portanto, o equilíbrio entre supervisão e autonomia é o grande desafio da engenharia de dados atual.
A Perspectiva da Neurociência: Como o Cérebro Aprende?
Como estamos no NeuroDataAI, é impossível ignorar a conexão biológica. Curiosamente, o cérebro humano utiliza uma combinação híbrida de ambos os métodos. Primeiramente, grande parte do nosso aprendizado inicial é não supervisionado. Por exemplo, um bebê aprende a distinguir formas, sons e texturas apenas pela exposição constante ao ambiente, sem que ninguém diga o nome de cada objeto. Isto é, o sistema visual humano agrupa padrões estatísticos de luz e sombra para formar a percepção de profundidade.
Entretanto, à medida que crescemos, o aprendizado supervisionado ganha espaço através da linguagem e da educação formal. Sempre que uma criança aponta para um animal e um adulto diz “isso é um cachorro”, ocorre uma etapa de rotulação externa. Dessa forma, o cérebro ajusta suas conexões sinápticas com base no feedback social. Nesse sentido, o desenvolvimento da IA caminha para mimetizar essa flexibilidade, unindo a capacidade de descoberta do não supervisionado com a precisão do supervisionado.
O Meio-Termo: Aprendizado Semi-Supervisionado
Além das duas categorias principais, existe uma abordagem intermediária que vem ganhando força: o aprendizado semi-supervisionado. Basicamente, este método utiliza uma pequena quantidade de dados rotulados combinada com uma vasta quantidade de dados não rotulados. Isso é particularmente útil em cenários como a análise de postagens em redes sociais ou diagnósticos médicos complexos, onde rotular tudo seria impossível.
O funcionamento técnico é fascinante: o algoritmo usa os poucos dados rotulados para aprender uma base e, em seguida, aplica esse conhecimento para rotular o restante dos dados de forma automática. Posteriormente, o modelo é refinado com esse novo conjunto expandido. Dessa maneira, conseguimos o melhor dos dois mundos: a orientação do supervisionado e a escala do não supervisionado. Portanto, esta técnica é frequentemente a solução para empresas que buscam alta performance com orçamentos limitados de curadoria de dados.
Métricas de Sucesso: Como Saber se o Modelo Funciona?
A avaliação de modelos é onde a diferença entre supervisionado e não supervisionado fica mais evidente. No caso do aprendizado supervisionado, temos o “gabarito” da prova. Assim sendo, podemos calcular exatamente quantas vezes o modelo acertou ou errou através de métricas como:
- Acurácia: A proporção de acertos totais.
- Precisão e Recall: Vitais para problemas onde o erro de um tipo é mais grave que o de outro (ex: não detectar uma doença).
- AUC-ROC: Que mede a capacidade do modelo de distinguir entre classes.
Contudo, no aprendizado não supervisionado, não existe uma “verdade absoluta”. Por essa razão, utilizamos métricas internas de coesão e separação. Por exemplo, o Silhouette Score mede o quão próximo um dado está do seu próprio grupo em comparação com outros grupos. Ainda assim, a palavra final muitas vezes cabe ao especialista do domínio (o humano), que deve validar se os grupos criados fazem sentido para o negócio ou para a ciência.
Aplicações Práticas: Da Medicina ao Marketing
Para ilustrar a relevância dessas técnicas, vamos analisar casos de uso reais que impactam a sociedade em 2026.
No Setor de Saúde e Neurotecnologia
Utiliza-se o aprendizado supervisionado para prever crises epilépticas a partir de dados de EEG. Como os dados históricos mostram os momentos exatos das crises anteriores, o modelo aprende os padrões que antecedem o evento. Por outro lado, o aprendizado não supervisionado é usado para descobrir novos subtipos de doenças mentais, agrupando pacientes por sintomas e biomarcadores genéticos que antes eram considerados uma única patologia.
No Marketing e E-commerce
O aprendizado não supervisionado é o rei da segmentação de clientes. Dessa forma, empresas conseguem identificar grupos de consumidores com comportamentos únicos sem precisar definir categorias prévias. Já o aprendizado supervisionado entra na fase de recomendação: após entender os grupos, o modelo prevê qual produto específico um usuário tem maior probabilidade de comprar, baseando-se no histórico de cliques rotulados.
Desafios Matemáticos: Maldição da Dimensionalidade
Um aspecto técnico que não podemos ignorar é a “Maldição da Dimensionalidade”. Sempre que aumentamos o número de variáveis (dimensões) em um dataset, o volume do espaço de dados cresce de forma exponencial, tornando os dados esparsos. Isso é um pesadelo tanto para o supervisionado quanto para o não supervisionado.
Nesse cenário, o aprendizado não supervisionado torna-se um herói através da redução de dimensionalidade. Técnicas como o PCA (Análise de Componentes Principais) permitem projetar esses dados em um espaço menor, eliminando o ruído e mantendo apenas o que importa. Consequentemente, isso melhora a performance dos modelos supervisionados que virão a seguir no pipeline de produção. Portanto, a integração entre os dois métodos não é apenas comum, é muitas vezes obrigatória para o processamento de Big Data.
Visão 2030: O Futuro com o Aprendizado por Reforço
Embora tenhamos focado nas duas vertentes principais, o futuro aponta para uma convergência ainda maior através do Aprendizado por Reforço (Reinforcement Learning). Até 2030, a distinção entre supervisionado e não supervisionado poderá se tornar menos rígida. Isto porque os sistemas de IA serão capazes de aprender em ambientes dinâmicos, recebendo recompensas e punições em vez de rótulos estáticos.
Dessa maneira, teremos agentes de inteligência artificial que exploram o mundo de forma não supervisionada para construir modelos mentais e, em seguida, refinam suas habilidades através de supervisão humana ou por metas específicas. Nesse sentido, o papel do Cientista de Dados evoluirá de um “treinador de modelos” para um “arquiteto de ecossistemas de aprendizado”. Em suma, o domínio das bases que discutimos hoje é o que garantirá a sua relevância na próxima década tecnológica.
FAQ: Dúvidas Comuns de Machine Learning
Qual método é mais difícil de implementar?
Na verdade, a implementação técnica de ambos é facilitada por bibliotecas como Scikit-Learn ou PyTorch. No entanto, o aprendizado não supervisionado é mais difícil de validar, pois exige uma interpretação muito mais profunda dos resultados e uma compreensão sólida do domínio dos dados.
Posso usar os dois no mesmo projeto?
Com certeza. Inclusive, essa é a melhor prática. Primeiramente, você usa o aprendizado não supervisionado para entender seus dados e reduzir dimensões. Posteriormente, você usa o aprendizado supervisionado para construir o modelo preditivo final. Essa combinação é o que chamamos de pipeline de machine learning robusto.
O aprendizado supervisionado vai morrer com o avanço das IAs generativas?
Não, de forma alguma. Pelo contrário, as IAs generativas (como LLMs) dependem fortemente de uma etapa final de aprendizado supervisionado chamada RLHF (Reinforcement Learning from Human Feedback). Portanto, a supervisão humana continua sendo o “tempero” que torna as respostas das máquinas úteis e seguras.
Link interno:
Para aprofundar os conceitos e acessar tutoriais práticos, vale a pena visitar a categoria de Ciência de Dados do site:
👉 Como o cérebro aprende e o que isso ensina para a Inteligência Artificial
Link Externo: Scikit-learn – Supervised vs Unsupervised Learning (documentação oficial)
Conclusão: A Escolha Estratégica
Em conclusão, a decisão entre usar aprendizado supervisionado ou não supervisionado não deve ser baseada no que é mais moderno, mas sim na natureza do seu problema e na disponibilidade de dados. Se você possui rótulos e um objetivo claro, vá de supervisionado. Se você possui dados massivos e quer descobrir o desconhecido, o não supervisionado é o seu melhor aliado.
Portanto, como vimos ao longo deste guia de 2.200 palavras, a inteligência artificial de sucesso em 2026 é aquela que sabe transitar entre o rigor da supervisão e a liberdade da descoberta. Ao dominar essas duas linguagens, você não está apenas aprendendo algoritmos; você está aprendendo a decifrar a estrutura da informação no mundo moderno. Dessa forma, continue explorando, testando e, acima de tudo, integrando esses conhecimentos para construir soluções que realmente façam a diferença.
A escolha entre supervisionado e não supervisionado depende exclusivamente do seu problema de negócio e da qualidade dos seus dados. Enquanto o primeiro entrega precisão e previsibilidade, o segundo revela oportunidades invisíveis.
Qual destes modelos você está implementando no seu projeto atual? Deixe sua dúvida ou experiência nos comentários abaixo. Na NeuroDataAI, transformamos dados em conhecimento estratégico.
Pingback: O que é overfitting e underfitting em Machine Learning (com exemplos simples) - NeuroDataAI