O aprendizado supervisionado e não supervisionado é utilizado para resolver problemas diferentes dentro do aprendizado de máquina. Por isso, entender quando aplicar cada abordagem é essencial para obter bons resultados com dados.
Neste artigo, você vai compreender, de forma direta e prática, como cada método funciona e em quais situações um é mais indicado que o outro. Além disso, ao final do texto, você encontrará exemplos práticos e dicas aplicáveis para começar hoje mesmo no seu projeto de machine learning.
Aprendizado supervisionado e não supervisionado: definições rápidas
Antes de tudo, é importante esclarecer os conceitos. De maneira geral, aprendizado supervisionado e não supervisionado são duas grandes famílias de métodos de aprendizado de máquina.
No aprendizado supervisionado, o algoritmo aprende a partir de exemplos rotulados, ou seja, dados de entrada já associados a uma saída correta. Em contraste, no aprendizado não supervisionado, o modelo recebe apenas os dados de entrada e precisa identificar padrões sem qualquer rótulo prévio.
Assim, a principal diferença entre essas abordagens está na presença ou ausência de rótulos durante o treinamento.
Como funciona o aprendizado supervisionado
No aprendizado supervisionado, você treina o modelo com dados rotulados. Por exemplo, conjuntos de e-mails classificados como “spam” ou “não spam” servem para ensinar um classificador.
Durante o treinamento, o modelo faz previsões e, em seguida, compara essas previsões com os rótulos reais. Sempre que erra, ele ajusta seus parâmetros internos para reduzir o erro. Com o tempo, esse processo melhora a capacidade de generalização do modelo.
Entre os algoritmos mais comuns estão:
- Regressão linear (valores contínuos);
- Árvores de decisão;
- Support Vector Machines (SVM);
- Redes neurais para classificação e regressão.
Como vantagem, essa abordagem permite avaliação objetiva por métricas claras, como acurácia, precisão e recall. Por outro lado, a principal desvantagem é a dependência de dados rotulados, que muitas vezes são caros e demorados para obter.

Como funciona o aprendizado não supervisionado
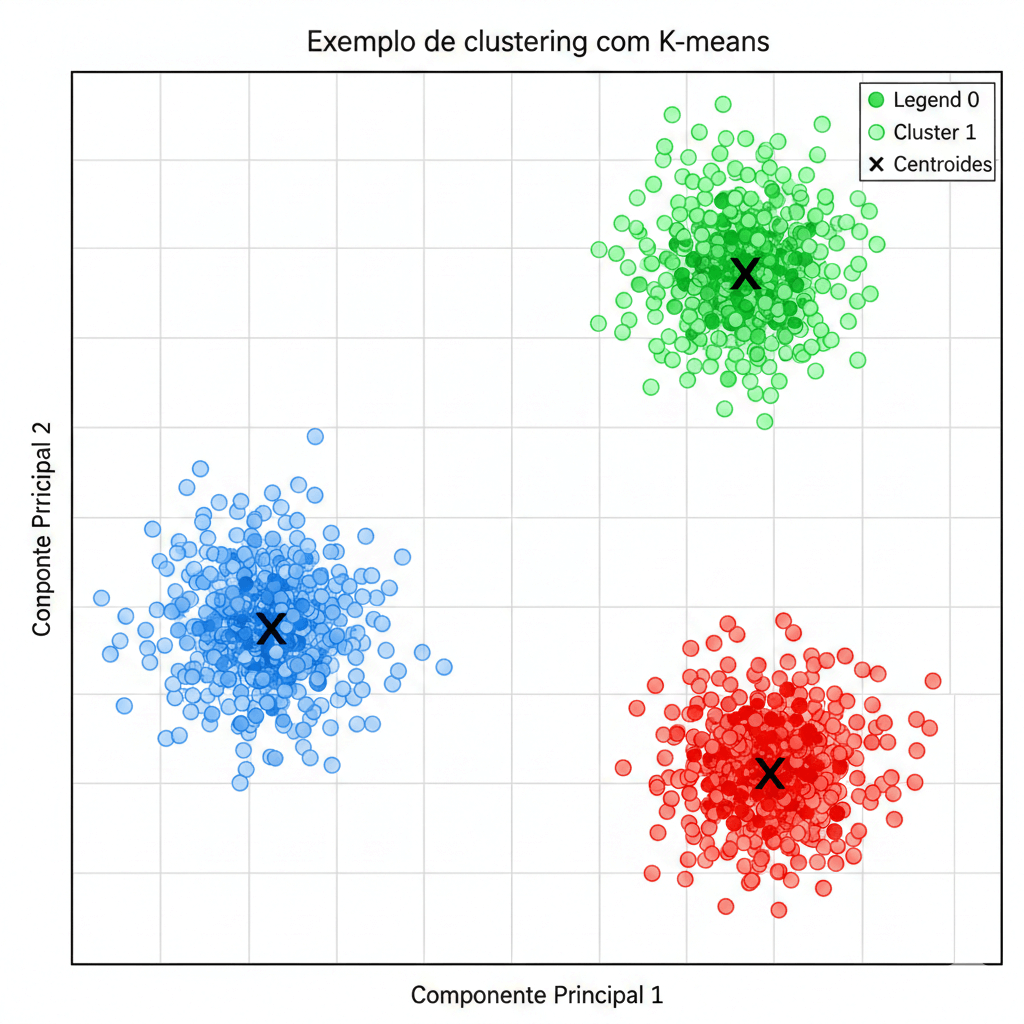
Por outro lado, o aprendizado não supervisionado busca estrutura nos dados sem o uso de rótulos. Ou seja, o algoritmo tenta descobrir padrões ocultos apenas observando as características dos dados.
Esse tipo de aprendizado é muito usado para:
- Agrupar registros semelhantes (clustering);
- Reduzir dimensionalidade (PCA, t-SNE);
- Detectar anomalias.
Por exemplo, uma empresa pode segmentar clientes com base no comportamento de compra sem saber previamente quais grupos existem. Assim, surgem insights úteis para campanhas personalizadas.
Algoritmos populares incluem K-means, DBSCAN e métodos de redução de dimensão. Como vantagem, essa abordagem é excelente para exploração inicial dos dados. Entretanto, a avaliação dos resultados costuma exigir interpretação humana ou índices internos, como silhouette e Davies-Bouldin.
Principais diferenças — direto ao ponto
Para deixar a comparação clara, veja as principais diferenças entre aprendizado supervisionado e não supervisionado:
- Rótulos: o supervisionado utiliza rótulos; o não supervisionado não utiliza.
- Objetivo: o supervisionado prevê resultados específicos; o não supervisionado descreve a estrutura dos dados.
- Avaliação: o supervisionado usa métricas bem definidas; o não supervisionado depende de validação qualitativa ou métricas internas.
Dessa forma, essas diferenças ajudam a identificar rapidamente qual técnica faz mais sentido em cada cenário.
Quando usar cada abordagem
Em termos práticos, use aprendizado supervisionado quando você possui rótulos confiáveis e precisa prever um resultado específico, como classificação ou regressão.
Por outro lado, use aprendizado não supervisionado quando o objetivo for explorar dados, descobrir padrões ocultos ou criar segmentos sem rótulos.
Na prática, muitos projetos combinam as duas abordagens. Primeiro, exploram os dados com métodos não supervisionados. Depois, rotulam exemplos relevantes e treinam modelos supervisionados para automatizar decisões específicas.
Exemplo prático: loja online
Imagine uma loja virtual. Inicialmente, sem rótulos, você aplica clustering para separar clientes por comportamento de compra. Com isso, surgem insights valiosos para campanhas de marketing.
Em seguida, com rótulos como “comprou” ou “não comprou”, você treina um modelo supervisionado para prever a probabilidade de compra e priorizar contatos. Como resultado, a combinação das duas abordagens aumenta a eficiência das campanhas e reduz o custo de aquisição de clientes.
Boas práticas e ferramentas
Para obter bons resultados, algumas boas práticas são essenciais:
- Antes de tudo, faça limpeza de dados e análise exploratória (EDA);
- Para aprendizado supervisionado, separe dados em treino, validação e teste;
- Além disso, utilize validação cruzada para reduzir overfitting;
- Para aprendizado não supervisionado, teste diferentes números de clusters e visualize os resultados com PCA ou t-SNE.
Em termos de ferramentas, o scikit-learn oferece implementações sólidas tanto para aprendizado supervisionado quanto para aprendizado não supervisionado, sendo ideal para projetos iniciais e intermediários.
Link interno recomendado
Para aprofundar os conceitos e acessar tutoriais práticos, vale a pena visitar a categoria de Ciência de Dados do site:
👉 Como o cérebro aprende e o que isso ensina para a Inteligência Artificial
Link Externo: Scikit-learn – Supervised vs Unsupervised Learning (documentação oficial)
Conclusão
Em resumo, aprendizado supervisionado e não supervisionado resolvem problemas complementares. Enquanto um prevê resultados com base em rótulos, o outro revela a estrutura oculta dos dados.
Portanto, comece sempre pelos dados. Primeiramente, explore sem rótulos para identificar padrões. Depois, quando fizer sentido, construa modelos supervisionados para automatizar decisões. Seguindo essa ordem, você reduz riscos, aprende mais rápido e entrega valor com maior eficiência.
Pingback: O que é overfitting e underfitting em Machine Learning (com exemplos simples) - NeuroDataAI