Atualmente, vivemos num mundo onde o volume de informação gerada ultrapassa a nossa capacidade inata de processamento. Nesse sentido, é fundamental compreender que, embora a Inteligência Artificial receba todos os holofotes, ela é apenas a ponta de um iceberg tecnológico massivo. Dessa forma, para que um modelo de IA funcione com precisão, existe uma infraestrutura invisível e complexa operando nos bastidores. Portanto, a Engenharia de Dados surge não apenas como uma disciplina técnica, mas como a verdadeira espinha dorsal que sustenta a inovação moderna.
Ao longo deste artigo, exploraremos como esta área se tornou o alicerce fundamental para qualquer projeto de dados bem-sucedido. Além disso, faremos paralelos fascinantes entre o processamento biológico e o digital. Consequentemente, ao final desta leitura, terá uma visão holística e profunda sobre como os dados brutos são transformados na inteligência que move o mundo atual.

O que é, de fato, a Engenharia de Dados?
Para iniciarmos esta análise, é necessário definir o escopo real desta profissão. A Engenharia de Dados consiste na prática de projetar, construir e manter sistemas que permitem o fluxo de dados em larga escala. Em outras palavras, enquanto o Cientista de Dados foca na extração de insights e na criação de modelos preditivos, o Engenheiro de Dados foca em garantir que o ecossistema seja robusto, escalável e confiável.
A Fundação da Pirâmide de Necessidades
Sob o mesmo ponto de vista, podemos imaginar uma pirâmide de necessidades para a IA. Na base, temos a recolha e o armazenamento; no topo, temos a Inteligência Artificial. Dessa maneira, se a base for frágil, toda a estrutura colapsa. Portanto, a Engenharia de Dados ocupa os degraus mais críticos dessa pirâmide. Além disso, o engenheiro deve lidar com o princípio GIGO (Garbage In, Garbage Out). Visto que, se alimentarmos um algoritmo com dados de má qualidade, o resultado será inevitavelmente um erro catastrófico, porém executado em alta velocidade.
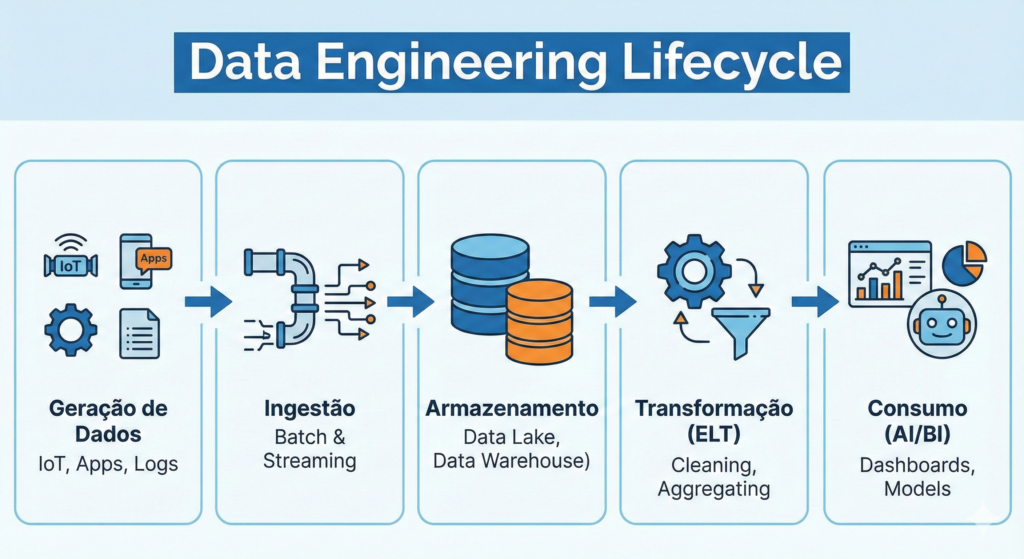
O Ciclo de Vida da Engenharia de Dados: Um Fluxo Contínuo
Uma vez que compreendemos a definição, precisamos mergulhar no ciclo de vida dos dados. Este processo não é estático; pelo contrário, ele é dinâmico e exige uma monitorização constante para garantir a integridade da informação.
A. Geração e Ingestão de Dados
Em primeiro lugar, os dados nascem de fontes heterogéneas, como sensores de IoT, transações bancárias ou logs de aplicações. Nesse estágio, o desafio reside na velocidade de captura. Por exemplo, sistemas de streaming capturam dados em tempo real, enquanto processos de batch lidam com grandes volumes em intervalos programados. Consequentemente, o engenheiro precisa de decidir qual a melhor arquitetura para cada caso de uso específico.
B. Armazenamento e Organização
Após a ingestão, os dados precisam de um local para “viver”. Antigamente, utilizavam-se apenas bancos de dados relacionais. No entanto, com o advento do Big Data, surgiram os Data Lakes e os Data Lakehouses. Dessa forma, conseguimos armazenar petabytes de informação de forma económica e acessível. Além disso, esta camada de armazenamento deve ser organizada de tal maneira que a recuperação da informação seja instantânea, evitando gargalos no processamento.
C. Transformação e Refinação
Ademais, os dados brutos raramente estão prontos para uso imediato. Geralmente, eles contêm ruído, valores ausentes ou formatos inconsistentes. Por esse motivo, a etapa de transformação é o coração da engenharia. Atualmente, o paradigma mudou do tradicional ETL (Extract, Transform, Load) para o ELT. Nesse novo modelo, os dados são carregados primeiro e transformados dentro do próprio armazém de dados, aproveitando o imenso poder de processamento da nuvem.
Engenharia de Dados vs. Ciência de Dados: Uma Simbiose Necessária
Frequentemente, existe uma confusão sobre os papéis destas duas áreas. Contudo, é essencial entender que elas são complementares e não competitivas. Para ilustrar, imagine a construção de um arranha-céus.
- O Engenheiro de Dados: É o arquiteto e o engenheiro civil que garante que as fundações, a canalização e a rede elétrica suportem o edifício. Dessa maneira, ele foca na infraestrutura.
- O Cientista de Dados: É o decorador de interiores e o analista de uso do espaço, que transforma o ambiente num local habitável e funcional. Portanto, ele foca no valor final entregue ao utilizador.
Em suma, sem o engenheiro, o cientista não tem matéria-prima. Em contrapartida, sem o cientista, o trabalho do engenheiro é apenas um armazém de ferro e betão sem propósito. Nesse sentido, A NeuroDataAI acredita que a colaboração estreita entre estas funções é o que define as empresas líderes de mercado.
O Paralelo Neurobiológico: O Sistema Nervoso do Big Data
No que diz respeito à nossa filosofia n’A NeuroDataAI, é impossível ignorar a semelhança entre os pipelines de dados e o sistema nervoso humano. De fato, o nosso cérebro é o processador de dados mais eficiente do universo conhecido.
Filtragem Sensorial e Pré-processamento
O cérebro recebe biliões de estímulos por segundo através dos nossos sentidos. Contudo, apenas uma fração mínima chega à consciência. Isso acontece porque o nosso tálamo atua como um engenheiro de dados, filtrando o ruído e priorizando a informação relevante. Dessa forma, quando um engenheiro cria um filtro de qualidade num pipeline, ele está a replicar um mecanismo biológico de milénios.
Latência e Reflexos
Do mesmo modo, a latência é um conceito crítico em ambos os mundos. Para exemplificar, quando tocamos numa superfície quente, a informação viaja e gera uma resposta motora em milissegundos. Consequentemente, num sistema de IA de um carro autónomo, a engenharia de dados de streaming deve garantir que a latência seja baixa o suficiente para evitar um acidente. Portanto, a eficiência da “espinha dorsal” digital determina a sobrevivência do sistema no mundo real.
A Stack Tecnológica Moderna: Ferramentas de Alta Performance
Para além da teoria, a engenharia de dados exige o domínio de ferramentas poderosas. Atualmente, o mercado é dominado por tecnologias distribuídas que permitem processar volumes de dados impossíveis para um único computador.
Linguagens de Programação e SQL
Em primeiro lugar, o SQL continua a ser a linguagem universal. Mesmo com o surgimento de novas tecnologias, a capacidade de consultar bases de dados de forma estruturada é indispensável. Além disso, o Python tornou-se a “cola” do ecossistema, permitindo a automação de processos complexos. Dessa maneira, a combinação de SQL e Python forma a base de competências de qualquer engenheiro de sucesso.
Big Data e Orquestração
Posteriormente, temos ferramentas como o Apache Spark, que permite o processamento paralelo em larga escala. Ademais, para gerir todos estes processos, utilizamos orquestradores como o Apache Airflow. Nesse contexto, o Airflow atua como o maestro de uma orquestra, garantindo que cada tarefa seja executada no momento exato e na ordem correta. Portanto, estas ferramentas garantem que a complexidade não se transforme em caos.
Big Data e os 5 V’s: O Desafio da Escala
A fim de compreender a magnitude do trabalho do engenheiro, devemos analisar os 5 V’s do Big Data. Cada um destes pilares apresenta um desafio técnico único que a engenharia de dados precisa de resolver.
- Volume: A quantidade de dados gerados é astronómica. Dessa forma, o engenheiro deve projetar sistemas que escalem horizontalmente.
- Velocidade: A rapidez com que os dados entram no sistema exige pipelines de streaming ultra-eficientes.
- Variedade: Dados estruturados, semi-estruturados (JSON) e não estruturados (imagens/vídeo) precisam de coexistir. Consequentemente, a arquitetura deve ser flexível.
- Veracidade: A confiança nos dados é fundamental. Sem dúvida, este é o maior desafio, pois dados errados levam a modelos enviesados.
- Valor: No final do dia, o dado deve gerar lucro ou conhecimento. Todavia, o valor só é extraído se os quatro V’s anteriores estiverem bem geridos.
Qualidade de Dados e Observabilidade: O Novo Patamar
Atualmente, não basta apenas construir o pipeline; é preciso garantir que ele está “saudável”. Nesse sentido, surge o conceito de Observabilidade de Dados. Tal como um médico monitoriza os sinais vitais de um paciente, o engenheiro de dados utiliza ferramentas para monitorizar a saúde dos fluxos de informação.
DataOps e Governança
Além disso, a metodologia DataOps aplica os princípios de agilidade do desenvolvimento de software ao mundo dos dados. Dessa maneira, conseguimos detetar falhas em tempo real antes que elas afetem o utilizador final. Portanto, a governança de dados garante que a informação seja tratada com ética e em conformidade com leis como a LGPD. Afinal, n’A NeuroDataAI, acreditamos que a segurança da informação é tão importante quanto a sua utilidade.
O Futuro: A Inteligência Artificial a Construir Pipelines
Finalmente, devemos olhar para o que vem a seguir. Estamos a entrar numa era onde a própria IA começará a auxiliar na engenharia de dados. Para ilustrar, já existem modelos que sugerem otimizações de consultas SQL ou que identificam anomalias nos dados automaticamente. No entanto, isso não significa que o engenheiro se tornará obsoleto. Pelo contrário, ele deixará de fazer tarefas repetitivas para se focar na arquitetura estratégica e na resolução de problemas complexos.
Link interno: Veja o nosso artigo Ciência de Dados vs Engenharia de Dados: Qual a Melhor Carreira?
Link externo: O que é o Apache Spark?
Conclusão: O Poder da Infraestrutura n’A NeuroDataAI
Em conclusão, a Engenharia de Dados é o alicerce invisível que permite que a magia da Inteligência Artificial aconteça. Embora o público se maravilhe com modelos de linguagem e carros que conduzem sozinhos, o verdadeiro herói é o sistema que garante que cada bit de informação chegue ao destino certo, na hora certa e com a qualidade necessária.
Para você, que acompanha A NeuroDataAI, entender a engenharia de dados é o primeiro passo para ter uma visão crítica e profissional sobre a tecnologia. Portanto, se deseja construir algo duradouro no mundo da tecnologia, comece por fortalecer a sua espinha dorsal de dados. Afinal, de nada serve ter um cérebro brilhante se o sistema que o alimenta está falho.
Pingback: Análise de Dados e Tomada de Decisão: A Ciência por trás dos Insights - NeuroDataAI