A rotina de um cientista de dados normalmente começa com perguntas. Antes de qualquer linha de código, surge a reflexão: quais problemas precisam ser resolvidos hoje e quais dados estão disponíveis para isso? Nesse sentido, entender o dia a dia desse profissional é essencial para quem está avaliando entrar na área.
Neste artigo, você vai conhecer, em linguagem simples, como funciona a rotina de um cientista de dados, quais tarefas aparecem com mais frequência e quais habilidades são mais exigidas. Assim, o conteúdo é ideal para quem deseja compreender a profissão antes de começar a estudar.
Vale destacar que a rotina pode variar conforme o tipo de empresa e o projeto. Por exemplo, em startups, o cientista de dados costuma atuar em todas as etapas, desde a coleta até o deploy. Por outro lado, em empresas maiores, o trabalho tende a ser mais especializado. Apesar dessas diferenças, o objetivo central permanece o mesmo: transformar dados em decisões práticas.
A seguir, você confere um passo a passo de um dia típico, com exemplos reais e dicas para quem quer ingressar na área.

Manhã: planejar, checar e rodar análises iniciais
Geralmente, o dia começa com o alinhamento de prioridades. Em primeiro lugar, uma das tarefas mais comuns na rotina de um cientista de dados é revisar demandas: tickets abertos, mensagens de times de produto ou negócios e reuniões rápidas, como stand-ups.
Logo depois, vem a checagem técnica. Nessa etapa, o profissional verifica se os pipelines de dados rodaram corretamente e se houve falhas em integrações ou atualizações. Caso algum problema seja identificado, ele precisa ser resolvido antes de avançar.
Em seguida, ocorre a análise exploratória inicial. Nesse momento, o cientista abre seus notebooks (como Jupyter ou Colab), executa consultas em SQL e gera gráficos rápidos. Dessa forma, é possível identificar valores ausentes, outliers ou mudanças inesperadas nos dados.
Essa etapa é decisiva. Afinal, muitas decisões do restante do dia dependem do que é descoberto nessa análise preliminar.
Meio do dia: limpeza, modelagem e experimentos
Na prática, grande parte da rotina de um cientista de dados é dedicada à preparação dos dados. Por isso, limpeza e pré-processamento costumam consumir bastante tempo. Essa fase inclui normalização, tratamento de valores nulos, engenharia de features e balanceamento de classes.
Embora seja repetitiva, essa etapa é crítica. Isso porque modelos de qualidade dependem diretamente de dados bem tratados. Sem essa base, mesmo algoritmos avançados tendem a falhar.
Após preparar os conjuntos de treino e teste, começa a fase de modelagem. Nesse ponto, o cientista testa diferentes algoritmos, como regressão, árvores de decisão, SVM ou redes neurais. Além disso, avalia métricas relevantes, como AUC, precisão, recall ou RMSE.
A rotina também inclui tuning de hiperparâmetros, validação cruzada e comparação com modelos baseline. Em projetos mais exploratórios, essa etapa pode se estender por dias ou até semanas.
Tarde: interpretar resultados e comunicar insights
Embora a parte técnica seja importante, a comunicação ocupa um papel central na rotina de um cientista de dados. Depois de obter resultados, surge o desafio de transformá-los em recomendações práticas.
Por isso, o profissional cria dashboards, relatórios e apresentações para áreas como produto, marketing ou diretoria. Nesse processo, ele precisa explicar não apenas os resultados, mas também as limitações dos modelos, o nível de confiança das previsões e os riscos envolvidos.
Além disso, é comum participar da validação em produção. Ou seja, acompanhar testes A/B, monitorar métricas após o deploy e ajustar modelos conforme o comportamento real dos dados. Dessa forma, garante-se que as soluções continuem relevantes ao longo do tempo.
Tarefas recorrentes: automação, documentação e colaboração
Além das análises principais, a rotina inclui tarefas recorrentes de manutenção. Por exemplo, criar pipelines reproduzíveis com ferramentas como Airflow ou Prefect, versionar código e modelos com Git ou MLflow e documentar processos.
A automação é fundamental. Afinal, ela reduz retrabalho e libera tempo para análises de maior impacto estratégico.
Outro ponto constante é a colaboração. Diariamente, o cientista de dados interage com engenheiros de dados, desenvolvedores e especialistas de negócio. Reuniões para alinhar requisitos, revisar hipóteses e priorizar demandas fazem parte do cotidiano.
Ferramentas que aparecem no dia a dia
Para dar conta dessa rotina, diversas ferramentas são utilizadas. Entre as principais, destacam-se:
- Linguagens: Python (pandas, scikit-learn, PyTorch) e, em alguns times, R
- Dados: SQL, BigQuery, Postgres
- Notebooks: Jupyter, Google Colab
- Orquestração: Airflow, Prefect
- Monitoramento e versionamento: MLflow, DVC, Grafana
- Visualização: matplotlib, seaborn, Plotly e ferramentas de BI como Looker e Power BI
Habilidades essenciais no cotidiano
Para lidar com essa diversidade de tarefas, algumas habilidades são indispensáveis.
Técnicas
- Programação e manipulação de dados (Python e SQL)
- Estatística aplicada e interpretação de métricas
- Machine Learning prático e experimentação
Comportamentais
- Curiosidade analítica para formular boas perguntas
- Comunicação clara para públicos não técnicos
- Organização e disciplina para documentar e replicar resultados
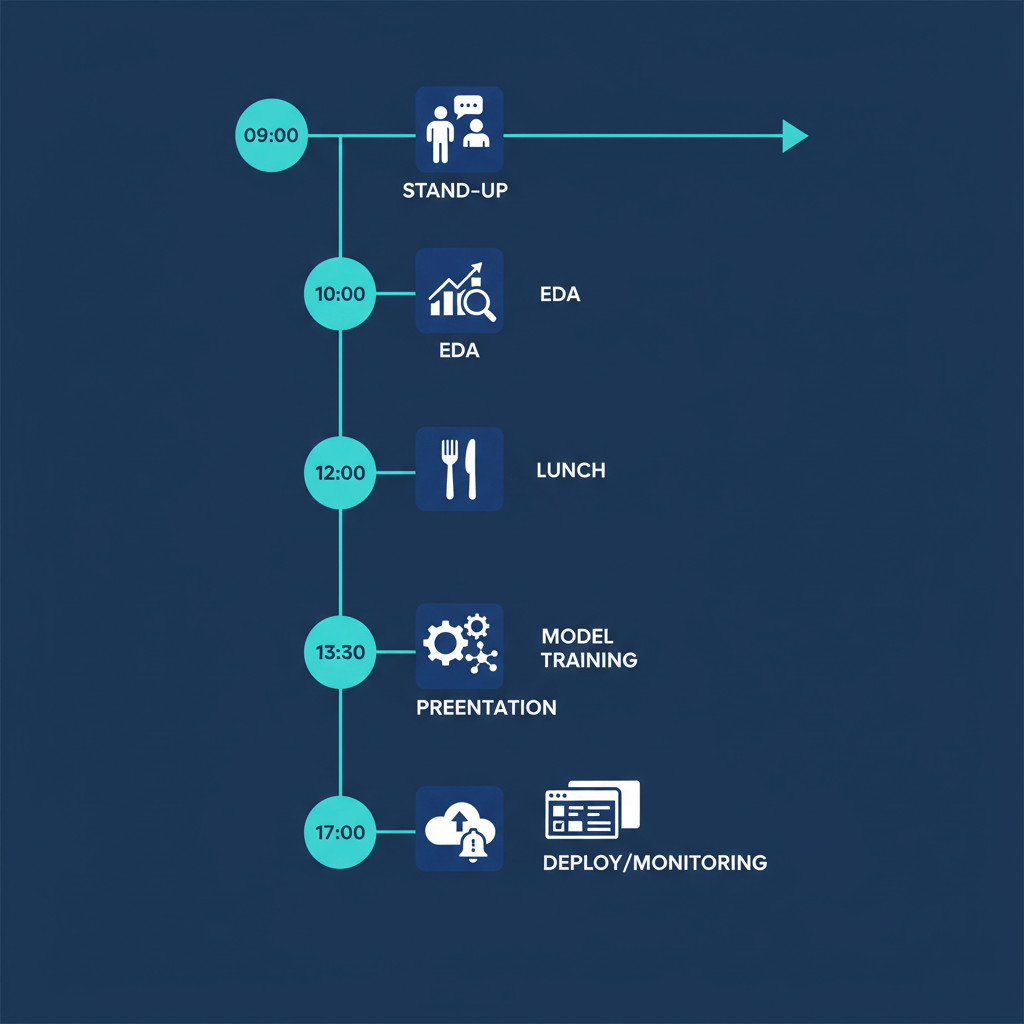
Exemplo prático de um dia real (resumido)
Para ilustrar melhor, veja um exemplo de rotina diária:
- 09:00 — Stand-up com a equipe e revisão de prioridades
- 09:30 — Conferir pipelines, logs e rodar consultas SQL
- 10:30 — EDA e limpeza de um novo dataset
- 12:00 — Almoço e leitura rápida de artigos
- 13:30 — Treinar modelos e comparar métricas
- 15:30 — Preparar slides e dashboards para reunião
- 17:00 — Deploy de versão de teste e configuração de monitoramento
Link interno: Veja o nosso artigo O que é Ciência de Dados? Guia completo para iniciantes em IA e Machine Learning
Conclusão: rotina dinâmica e orientada a impacto
Em resumo, a rotina de um cientista de dados é dinâmica e fortemente orientada à resolução de problemas. Ao mesmo tempo, envolve uma parte técnica intensa e uma parte estratégica focada em comunicação e impacto.
Quem gosta de analisar dados, resolver problemas reais e explicar resultados de forma clara tende a se identificar com essa carreira. Portanto, se você quer começar, foque em Python, SQL, estatística e, principalmente, em projetos práticos que demonstrem sua capacidade de transformar dados em decisões.