O Despertar da Maturidade Digital em 2026
Atualmente, o cenário tecnológico global atravessa um momento de profunda sobriedade. Após a febre inicial da Inteligência Artificial Generativa, as organizações compreenderam que o brilho dos modelos de linguagem não se sustenta sem um alicerce sólido. Nesse sentido, o ano de 2026 marca a transição das soluções experimentais para a engenharia de precisão. Entender a interdependência entre Engenharia de Dados e Big Data tornou-se a fronteira final entre empresas que apenas “consomem” tecnologia e aquelas que lideram mercados inteiros através da inteligência estratégica.
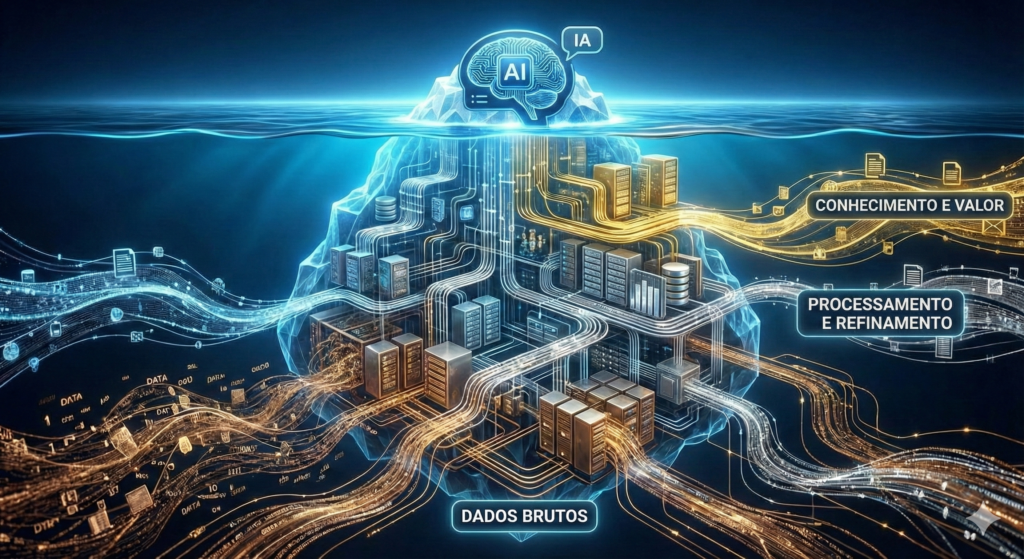
Dessa forma, é preciso encarar a IA como a ponta de um iceberg gigantesco. Enquanto as interfaces de conversação e os algoritmos de predição ocupam a parte visível, a massa crítica submersa — composta por pipelines resilientes, curadoria de qualidade e governança rigorosa — é o que realmente garante a estabilidade de toda a estrutura. Portanto, este guia exaustivo da A NeuroDataAI detalha cada engrenagem desse maquinário invisível, revelando como transformar o caos informacional em um motor de inovação sem precedentes.
O Choque de Realidade: Por que a IA Falha sem Engenharia?
Primeiramente, é necessário desmistificar a crença de que um algoritmo potente pode compensar dados de má qualidade. No domínio da Ciência de Dados, o princípio Garbage In, Garbage Out (GIGO) é uma lei física absoluta. Se um modelo de Machine Learning for alimentado com dados enviesados, inconsistentes ou desatualizados, o resultado será uma ferramenta que toma decisões equivocadas com alta velocidade e confiança.
O Custo do Lixo Informacional e o “Data Drift”
Sob essa ótica, o papel do engenheiro de dados é atuar como o refinador de combustível para a inteligência. De fato, estima-se que cientistas de dados ainda gastem cerca de 70% a 80% do seu tempo limpando dados brutos. Nesse contexto, a Engenharia de Dados e o Big Data trabalham para automatizar essa limpeza, combatendo fenômenos como o Data Drift (onde os dados mudam ao longo do tempo, invalidando o modelo). Consequentemente, ao industrializar o processamento, permitimos que a IA opere em sua máxima capacidade, evitando “alucinações” causadas por fontes contraditórias.
A Anatomia dos Pipelines de Dados Modernos
Para que uma infraestrutura seja resiliente, ela deve ser construída sobre processos bem definidos. Na A NeuroDataAI, estruturamos o ciclo de vida do dado em quatro fases críticas que transformam o “petróleo bruto” informacional em ativo de valor.
A. Ingestão: A Captura do Caos
Atualmente, os dados chegam de milhares de fontes simultâneas: sensores de IoT, transações de e-commerce, interações em redes sociais e logs de servidores. Nesse momento, a engenharia deve decidir entre dois padrões:
- Batch Processing (Processamento em Lote): Ideal para grandes volumes históricos onde a latência não é crítica.
- Stream Processing (Processamento em Tempo Real): Utilizando ferramentas como Apache Kafka ou Flink, é essencial para detecção de fraudes e personalização imediata do usuário.
B. O Paradigma ELT (Extract, Load, Transform)
No que diz respeito à movimentação de dados, o antigo modelo ETL deu lugar ao ELT. Antigamente, transformávamos os dados antes de carregá-los, o que criava gargalos. Hoje, com o poder da nuvem, carregamos os dados brutos no Data Lake e realizamos a transformação internamente. Dessa maneira, preservamos a linhagem original da informação e ganhamos flexibilidade para futuras reanálises.
C. Qualidade e Enriquecimento
Adicionalmente, o dado carregado precisa ser validado. Isso significa verificar a integridade de campos, remover duplicatas e cruzar informações de diferentes fontes para gerar contexto. Afinal, um dado isolado é apenas um número; um dado enriquecido é conhecimento.
Big Data em 2026: Os 7 Vs da Inteligência
Embora o conceito original de Big Data focasse em 3 Vs (Volume, Velocidade e Variedade), a era da IA exigiu a expansão dessa teoria para sete pilares fundamentais.
- Volume: Já não falamos de Terabytes, mas de Exabytes. O desafio é o armazenamento distribuído e de baixo custo.
- Velocidade: A IA agêntica exige respostas em milissegundos. Dessa forma, a latência tornou-se o principal inimigo do engenheiro.
- Variedade: Integração de textos, imagens, vídeos e áudios em um único ecossistema multimodal.
- Veracidade: Em tempos de Deepfakes, garantir a autenticidade e a origem do dado é vital.
- Variabilidade: O sentido do dado muda conforme o contexto. A engenharia deve ser adaptável.
- Visualização: O dado precisa ser legível para humanos e máquinas.
- Valor: Acima de tudo, se o dado não reduz custos ou aumenta a receita, ele é apenas ruído acumulado.
Arquiteturas de Elite: Data Lakehouse e Medallion
No contexto de infraestrutura, a A NeuroDataAI recomenda a adoção da Arquitetura de Medalhão dentro de um ambiente Data Lakehouse. Esta abordagem combina a flexibilidade do Data Lake com a governança do Data Warehouse.
A Camada Bronze (Bruta)
Nesse estágio, armazenamos os dados exatamente como foram capturados, sem qualquer alteração. Portanto, se um erro ocorrer no processamento futuro, sempre podemos voltar à fonte original para reprocessar a informação.
A Camada Silver (Tratada)
Posteriormente, os dados passam por limpeza e padronização. Nesse nível, tabelas são criadas com tipos de dados consistentes e registros nulos são tratados. Basicamente, é aqui que o dado começa a ganhar forma útil para a análise técnica.
A Camada Gold (Negócio)
Por fim, os dados são agregados por regras de negócio. Isto é, eles são otimizados para consumo imediato por dashboards de BI ou para o treinamento de modelos de Inteligência Artificial. Consequentemente, a camada Gold é o produto final da refinaria de dados.
Tecnologias de Ponta: O Stack Tecnológico de 2026
Para dominar a Engenharia de Dados e Big Data, é necessário dominar um conjunto de ferramentas que permitam a computação distribuída e a automação.
Processamento Distribuído: Apache Spark e Dask
De acordo com os padrões da indústria, o processamento em memória do Spark continua sendo o rei da escala. Similarmente, o Dask vem ganhando espaço por sua integração nativa com o ecossistema Python, facilitando a transição entre engenheiros e cientistas de dados.
Orquestração de Pipelines: Airflow e Prefect
Nesse processo, a automação é o que garante a eficiência. Orquestradores permitem agendar tarefas complexas, gerir dependências e disparar alertas em caso de falhas. Ou seja, eles são o sistema nervoso que garante que o dado chegue no lugar certo, na hora certa.
Bancos de Dados Vetoriais: A Memória da IA
Certamente, a grande novidade tecnológica é a ascensão dos Bancos de Dados Vetoriais (como Pinecone e Milvus). Ao contrário dos bancos SQL tradicionais, eles armazenam vetores matemáticos que permitem buscas semânticas. Nesse sentido, eles são essenciais para sistemas de RAG (Retrieval-Augmented Generation), permitindo que LLMs consultem dados corporativos em tempo real sem alucinações.
Governança de Dados e a LGPD: O Escudo da Confiança
Embora a velocidade e a tecnologia sejam fascinantes, a segurança é inegociável. No Brasil, a conformidade com a LGPD exige que cada bit de informação tenha uma origem rastreável e um propósito claro.
Data Lineage (Linhagem de Dados)
Isto significa que a organização deve ser capaz de explicar exatamente por quais transformações um dado passou. Nesse cenário, ferramentas de catálogo de dados garantem a transparência. Afinal, se uma IA toma uma decisão discriminatória, a empresa precisa auditar o pipeline para identificar onde o viés foi introduzido.
Privacidade por Design
Portanto, a Engenharia de Dados e o Big Data devem ser projetados com a privacidade em mente desde o início. Dessa maneira, técnicas de anonimização e mascaramento de dados sensíveis são integradas diretamente nos pipelines de ingestão, garantindo que o cientista de dados treine modelos sem nunca acessar informações pessoais identificáveis.
DataOps e MLOps: A Industrialização da Inteligência
À medida que a disciplina amadurece, ela adota práticas inspiradas na engenharia de software tradicional. O surgimento do DataOps foca na entrega contínua de dados de alta qualidade.
- Monitoramento e Observabilidade: Detecção proativa de anomalias. Por exemplo, se o volume de dados de entrada cair 50% subitamente, o sistema avisa o engenheiro antes que o modelo de IA seja afetado.
- Testes Automatizados: Garantia de que novas mudanças no código do pipeline não quebrem a integridade dos dados históricos.
- Versionamento de Dados: Assim como versionamos código, agora versionamos conjuntos de dados para permitir o “rollback” em caso de corrupção informacional.
Desafios para o Futuro: Sustentabilidade e Green Data
No entanto, o processamento de Big Data consome quantidades massivas de energia. Em 2026, a eficiência não é apenas uma métrica financeira, mas ambiental.
Nesse sentido, a Engenharia de Dados e o Big Data estão migrando para o “Green Data Computing”. Dessa forma, otimizar consultas SQL e reduzir a movimentação desnecessária de dados entre servidores não apenas acelera a IA, mas também reduz a pegada de carbono dos Data Centers. Afinal, a inteligência artificial não pode custar a sustentabilidade do nosso planeta.
O Papel Estratégico da A NeuroDataAI na Sua Empresa
Se por um lado o desafio tecnológico é imenso, por outro, a recompensa é a liderança de mercado. A NeuroDataAI, entendemos que cada empresa possui uma maturidade de dados diferente.
Dessa forma, nossa abordagem foca em:
- Diagnóstico de Infraestrutura: Identificar pântanos de dados e silos informacionais.
- Arquitetura Customizada: Implementar Lakehouses que escalam conforme a necessidade do negócio.
- Cultura de Dados: Treinar equipes para que a engenharia e a ciência de dados falem a mesma língua.
Link interno: Veja o nosso artigo O Brasil Enfrentando o Burnout e a Ansiedade com Tecnologia
Biblioteca do Arquiteto de Dados
Se você deseja se aprofundar nos conceitos de pipelines e arquitetura distribuída que discutimos aqui, recomendo fortemente a leitura de Designing Data-Intensive Applications. É a base teórica para qualquer sistema de IA que pretenda sobreviver em 2026.”
🛡️Nota de Transparência: A NeuroDataAI acredita na integridade científica. Ao clicar nos links de livros recomendados, nós podemos receber uma pequena comissão pela indicação. Isso não altera o preço para você e ajuda a manter nossa infraestrutura de pesquisa e inteligência ativa. Só recomendamos o que realmente lemos e validamos.
Conclusão: O Investimento Inevitável no Alicerce
A jornada para uma Inteligência Artificial de sucesso não começa na escolha do modelo mais caro, mas na construção da refinaria de dados mais eficiente. Embora a Engenharia de Dados seja invisível para o usuário final, ela é o fator que determina se sua empresa terá uma bússola precisa ou se ficará perdida em um mar de ruído.
Portanto, o convite da NeuroDataAI é claro: pare de olhar apenas para a superfície do iceberg. Nesse sentido, invista no alicerce. Afinal, em 2026, os dados não são apenas o novo petróleo; eles são o sistema nervoso central da civilização digital. Aqueles que dominarem a arte de mover, limpar e governar esses dados serão os verdadeiros arquitetos do amanhã.